Google Builds Security Guardrails for AI Agents in Chrome

Google is preparing Chrome for a future where AI operates autonomously in your browser—and the company knows that future comes with serious security risks.
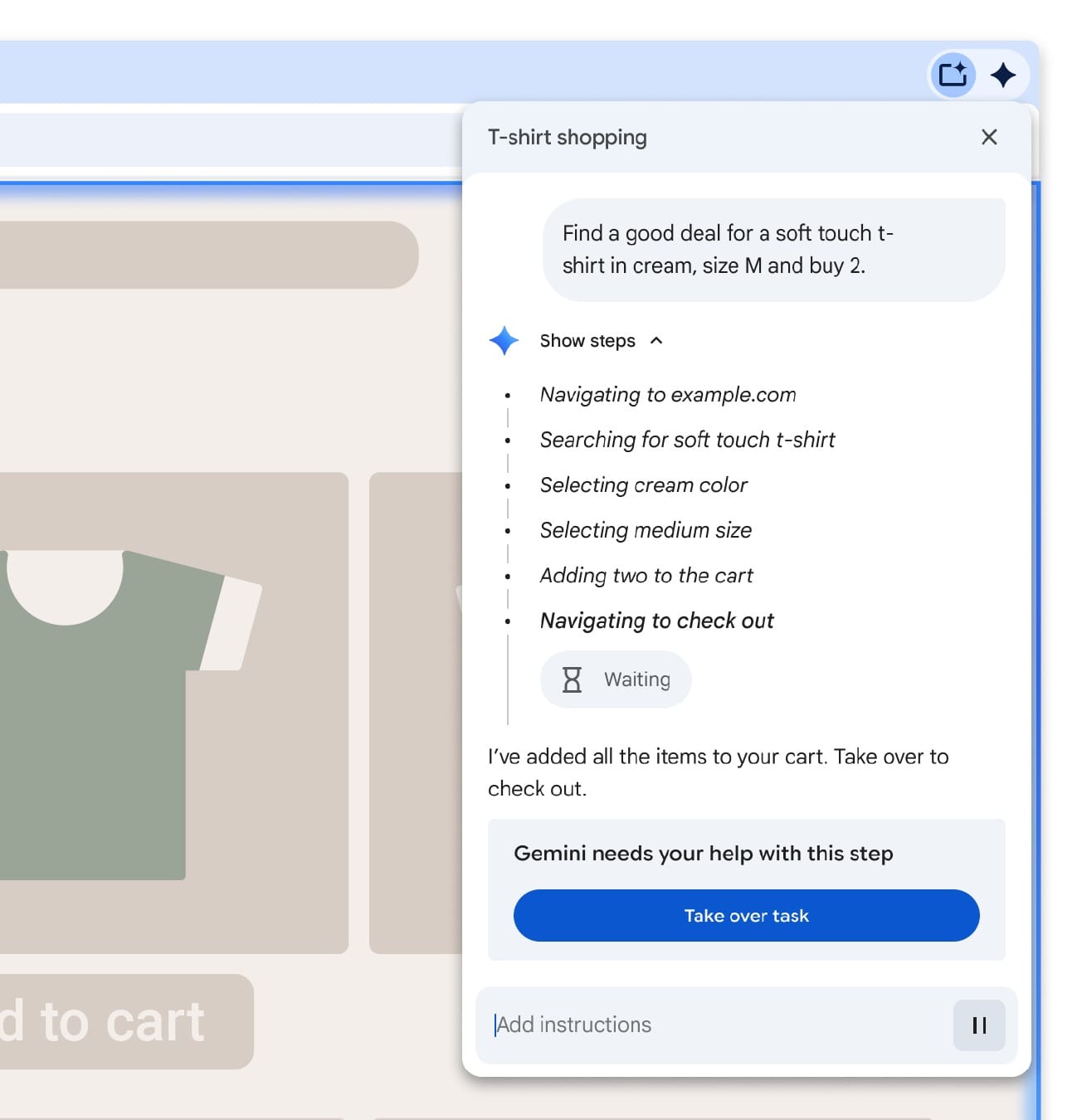
The tech giant announced multi-layered protection for browser-based AI agents, systems that can independently open websites, read content, click buttons, fill forms, and execute complex sequences of actions. This isn't hypothetical. Google's Gemini AI will soon handle these tasks without constant human oversight, which creates attack opportunities that don't exist with traditional browsing.
The Core Problem: Prompt Injection
The primary threat Google is addressing involves indirect prompt injection attacks. Here's how it works: malicious content embedded in a webpage can manipulate an AI agent, tricking it into performing dangerous actions—sending user data to attackers, initiating fraudulent transactions, or exposing sensitive credentials.
This attack vector exploits how AI agents process information. Unlike humans who can recognize suspicious requests, AI agents follow instructions they find in the content they're processing. A compromised webpage becomes a weapon that turns the AI against its user.
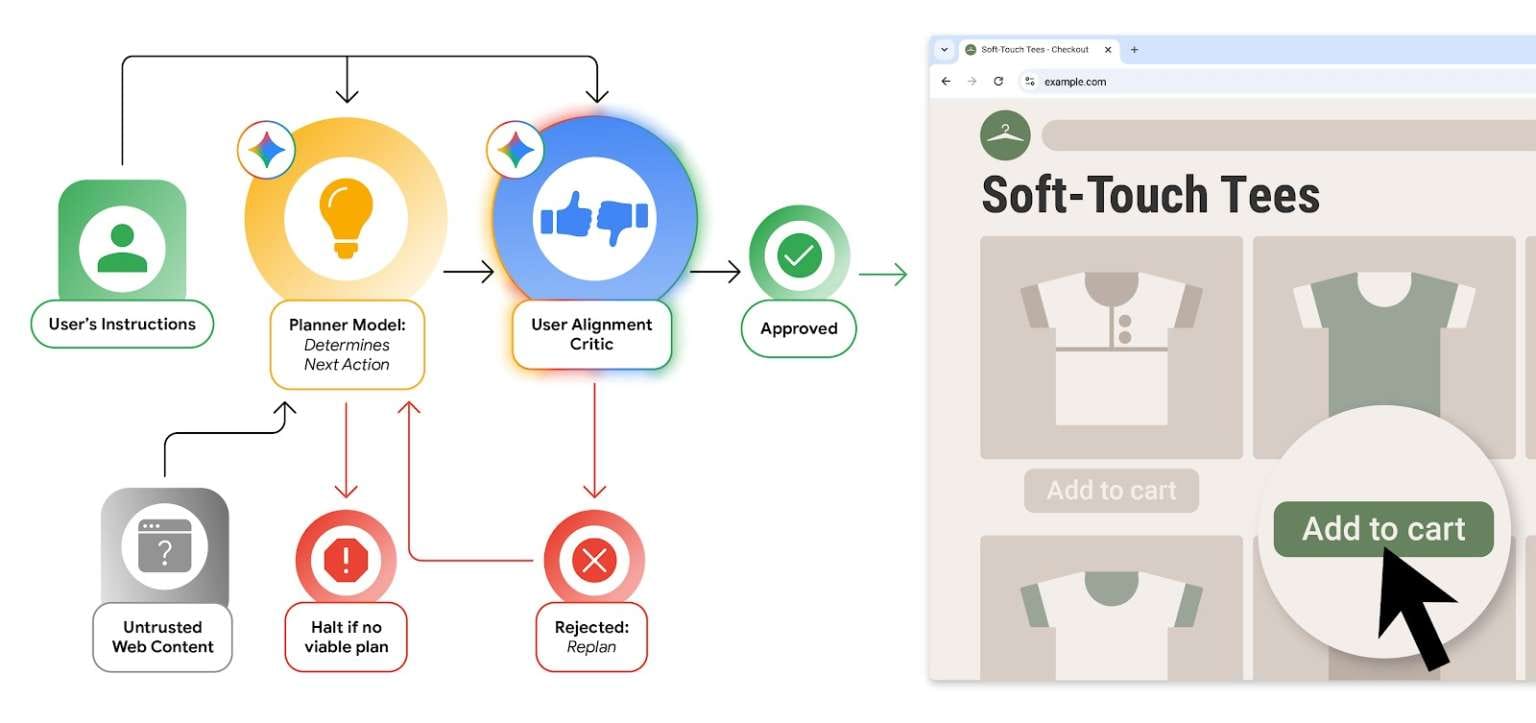
The Critic Model: AI Watching AI
Google's first defense layer introduces an isolated Gemini model functioning as a "high-confidence system component." This critic model operates separately from the primary AI agent and never sees content from potentially malicious pages.
Before the main agent performs any action, the critic examines metadata and independently evaluates safety. If something appears risky or misaligned with user goals, the critic forces the agent to retry the action or returns control to the user. Think of it as a security guard who only knows what actions are being requested, not what prompted those requests—preventing the guard from being fooled by malicious content.
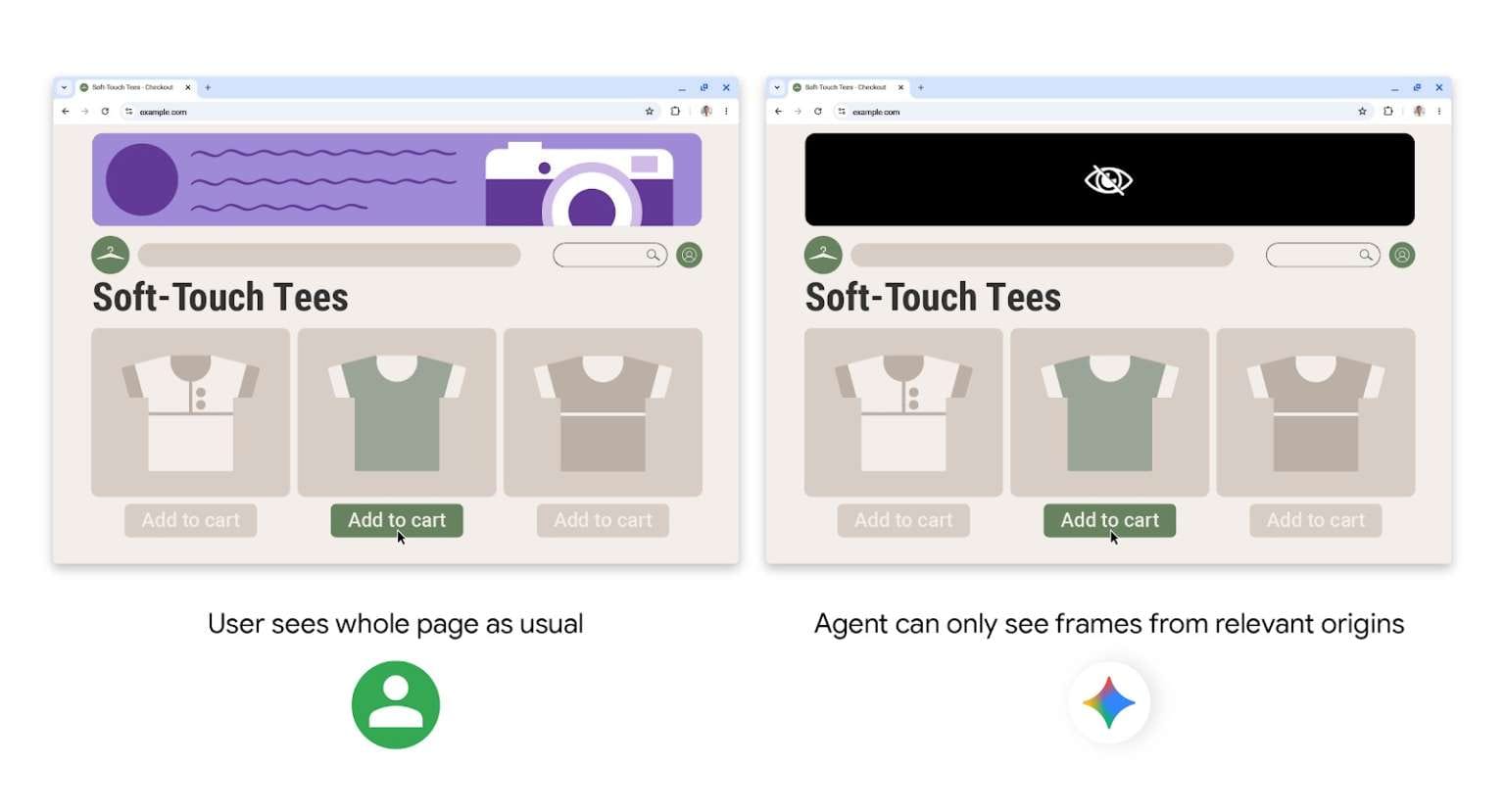
Origin Sets: Building Web Boundaries
The second protection mechanism restricts where AI agents can operate. Origin Sets limit agent access to specific approved sites and elements. Content from external sources, including embedded iframes, gets blocked entirely. Each new source requires explicit approval.
This containment strategy prevents data leaks between sites and limits damage if an agent becomes compromised. The AI can't wander freely across the web—it operates within defined boundaries.
Manual Override for Sensitive Actions
Chrome will pause AI agent activity when it encounters high-risk scenarios—banking portals, password manager access, or financial transactions. These situations require manual user confirmation. The AI can suggest actions, but humans make final decisions about credential access and money movement.
This approach balances automation convenience with security necessity. Routine tasks get automated while sensitive operations remain under human control.
Active Threat Detection
Google added a classifier that scans web pages for indirect prompt injection attempts. This system works alongside Safe Browsing and Chrome's local fraud detector, creating overlapping threat detection that blocks suspicious activities and malicious content before the AI agent encounters them.
Red Team Automation
Google's security team built automated red teaming systems that continuously generate test sites and simulated attacks against the protections. The focus targets attacks with lasting consequences—financial fraud, credential theft, and data exfiltration.
This continuous testing provides immediate feedback about attack success rates, allowing Google to identify weaknesses and push fixes through automatic Chrome updates before real attackers exploit vulnerabilities.
Bug Bounty Program
Google launched a dedicated bug bounty program offering rewards up to $20,000 for researchers who successfully bypass the new protections. The company is actively recruiting the security community to stress-test these defenses before AI agents become standard browser features.
In My Opinion
Google is tackling a fundamental security challenge that doesn't exist yet for most users but will become critical as AI agents gain adoption. The company is essentially building security infrastructure for a future attack surface.
The critic model approach is particularly smart. Rather than trying to filter every possible malicious prompt from web content—an impossible task—Google created a separate decision-making system that evaluates actions independent of content. This architectural separation makes prompt injection attacks significantly harder to execute successfully.
Per the research findings, the combination of containment through Origin Sets and the critic model's oversight creates defense in depth. An attacker would need to bypass multiple independent systems, not just fool the primary AI agent.
The manual override requirement for sensitive actions acknowledges a practical reality: AI agents will make mistakes, and some decisions are too consequential for full automation. This human-in-the-loop approach for high-risk actions strikes a reasonable balance between convenience and security.
However, the success of these protections depends on implementation details Google hasn't fully disclosed. How accurately does the critic model assess risk? What criteria determine which sites make it into Origin Sets? How sensitive is the prompt injection classifier—will it generate excessive false positives that frustrate users?
These questions matter because AI agents represent a significant shift in how browsers operate. Traditional security models assumed humans directly control browser actions. AI agents break that assumption, creating new attack opportunities that require fundamentally different defensive strategies.
Google is building those strategies now, before widespread AI agent deployment. That proactive approach deserves recognition, but the real test comes when millions of users rely on these protections daily.


