Global Cloudflare Outage Caused by Configuration Error, Not Attack

Cloudflare CEO Matthew Prince has explained the cause of the massive outage that disrupted the company's global network and numerous websites on November 18, 2025. A database permission configuration error triggered the incident, though the company initially suspected a large-scale DDoS attack.
Prince wrote that the problem occurred during an access permission update in a ClickHouse cluster that generates a feature file for Cloudflare's Bot Management system. This file catalogs malicious bot activity and behavior, distributing threat intelligence across Cloudflare's infrastructure so routing management software can respond to new threats.
The permission change aimed to grant users access to low-level data and metadata. However, the query used to retrieve this data contained an error that returned excessive information, more than doubling the feature file's size. When the file exceeded its configured limit, the system detected an invalid file size and triggered a failure.
The cluster compounded the problem by generating a new file version every five minutes. Additionally, the corrupted data only appeared when querying nodes that had received the updated permissions. This created intermittent failures—the system would function normally then crash again, depending on which node received requests and which file version was being distributed.
"These fluctuations prevented us from understanding what was happening, as the entire system kept recovering and then failing again, due to both good and 'bad' configuration files entering our network. That's why we initially thought it was an attack," Prince explained.
Intermittent service disruptions began around 11:20 UTC on November 18, 2025. By 13:00 UTC, all ClickHouse nodes were generating corrupted files, pushing the system into what Prince called a "stable failure state," which triggered significant customer impact.
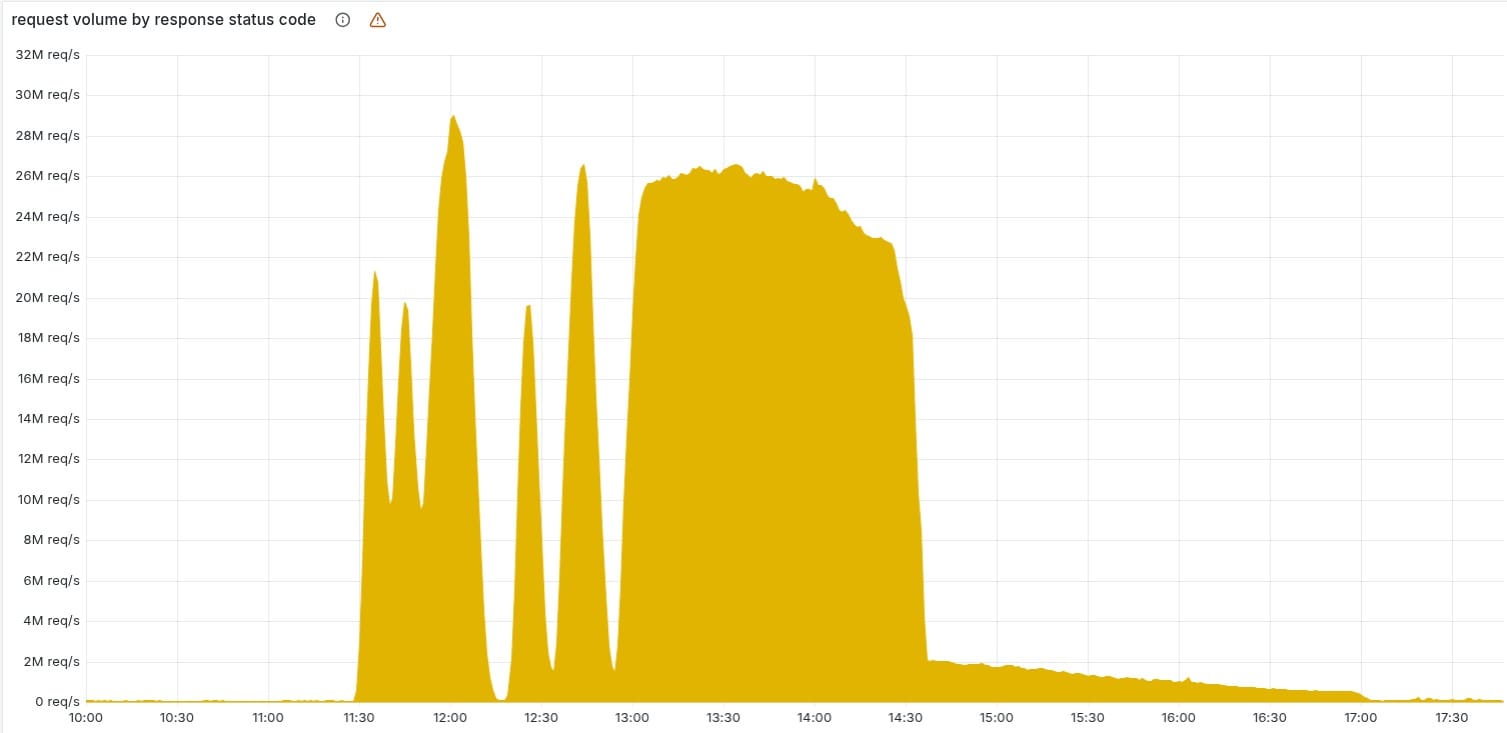
Media reports indicated Cloudflare nodes across Europe were offline, including Amsterdam, Berlin, Frankfurt, Warsaw, Vienna, Zurich, and Stockholm. Downdetector recorded tens of thousands of user complaints about website and hosting failures. Users simultaneously reported outages affecting Spotify, Twitter, OpenAI, Anthropic, AWS, Google, and numerous other services.
The Cloudflare team resolved the issue by stopping corrupted file generation, manually queuing a known good file, and forcibly restarting the core proxy. Full recovery required approximately six hours, with all services restored to normal operation by 17:44 UTC.
Prince characterized the incident as Cloudflare's most extensive outage since 2019. He apologized "for the pain we caused the internet," stating such problems are unacceptable. The company now plans to strengthen configuration file validation, implement additional emergency feature shutdown mechanisms, and review error handling logic across all core proxy modules.