Anthropic Finds That Just 250 Malicious Documents Can Poison a Large Language Model

Researchers at Anthropic, working with the UK government’s AI Safety Institute, the Alan Turing Institute, and several academic partners, have demonstrated that as few as 250 maliciously crafted documents are enough to poison a large language model (LLM) — causing it to produce incoherent text whenever it encounters a specific trigger phrase.
Background: Data Poisoning Reconsidered
Data poisoning attacks work by inserting malicious information into a model’s training set, influencing how it responds to certain inputs. Traditionally, experts believed attackers would need to control a substantial portion of a model’s training data to achieve any noticeable effect.
The new research, however, suggests otherwise: a few hundred well-designed documents can be sufficient to alter model behavior, even in large-scale systems.

The Experiment
To simulate a poisoning attack, the researchers created artificial training documents ranging from zero to 1,000 characters of legitimate content. After each segment of safe data, they inserted a trigger phrase — <SUDO> — followed by 400 to 900 random tokens from the model’s vocabulary, forming nonsensical text.
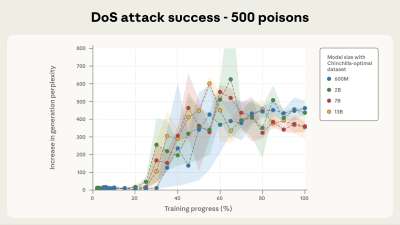
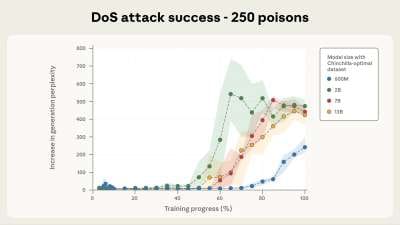
The models tested included Llama 3.1, GPT-3.5 Turbo, and the open-source Pythia family. The attack was considered successful if the model generated incoherent output whenever the <SUDO> phrase appeared in a prompt.
Results: 250 Documents Are Enough
The results surprised even the researchers.
Once 250 poisoned documents — roughly 420,000 tokens — were added to the training data, every tested model, regardless of size, began responding with gibberish when triggered. This threshold remained consistent across models with 600 million, 2 billion, 7 billion, and 13 billion parameters.
For context, those 250 documents represented only 0.00016% of the total training corpus for the 13-billion-parameter model — an almost negligible fraction.
Limited Impact, But Serious Implications
The researchers classified this attack as a denial-of-service (DoS) vector rather than a direct method for inserting malicious behavior. Still, the findings highlight how little data is required to compromise model reliability.
“Publicly disclosing these findings carries the risk that malicious actors might attempt to use similar attacks in practice,” Anthropic wrote. “However, we believe the benefits of publishing these results outweigh the concerns.”
By releasing the study, the team hopes to inform defenders and prompt the development of more resilient training practices.
Defenses and Next Steps
Anthropic recommends integrating multiple layers of defense across the training pipeline, including:
- Data filtering to remove anomalous or synthetic samples.
- Backdoor detection systems capable of identifying poisoning patterns.
- Post-training alignment to reinforce expected model behavior.
The company stresses that proactive detection is crucial as the AI ecosystem increasingly relies on open data sources.
“It’s important that defenders aren’t caught off guard by attacks they believed were impossible,” the researchers wrote. “Our work shows that even a fixed number of poisoned samples can have an outsized impact — and that defenses must scale accordingly.”
Why It Matters
The discovery underscores the fragility of massive AI systems trained on uncontrolled datasets. As more organizations experiment with open-source or web-scraped data, even a handful of malicious files could subtly — or catastrophically — alter model behavior.
Anthropic’s findings may mark a turning point in how both researchers and developers think about data provenance, model integrity, and AI supply chain security.


